Date: Sun Mar 25 21:12:09 2001
Posted By: Michael Onken, MadSci Admin
Area of science: Physics
ID: 985241074.Ph
Message:
Kim,
What a great question (and one of my favorites)! You're recognition of the
difference between the perceived "color wheel" and the linear spectrum of
visible light is reminiscent of the work of
Ernst Mach, who determined that our
perceptions were so filtered by our sensory organs that scientific
observations must be completely empirical to have merit; otherwise they are
measurements of our senses rather than phenomena. There are actually
several aspects of purple that require both physics and neuroscience to
explain, depending upon in which end of the purple spectrum you are
interested. As the common mnemonic for the colors of the rainbow,
ROYGBIV, suggests, after Blue come Indigo and Violet, such that if Blue
is set at a wavelength around 480 nm, then Indigo and Violet
would be about 440 nm and 390 nm, respectively.
So if violet (390 nm) and red (650 nm) mark the outer boundaries of the
visible spectrum, then where are the "intermediate" colors like magenta?
Well, they don't exist - at least not as discreet wavelengths of light!
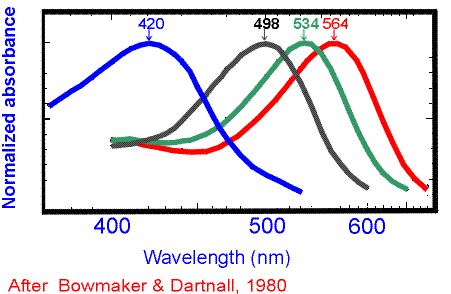 To understand this phenomenon we must turn, as Mach would have, to the
source of color perception, the retina. Colors are distinguished on the
retina by three different sets of cone cells, each of which detect broad peaks of
light centered around 420 nm ("blue" or short-
wavelenght cones), 534 nm ("green" or middle-
wavelength cones), and 564 nm ("red" or long-
wavelength cones). The retina assigns a "color" to a specific wavelength of
visible light according to which cones it stimulates at to what extent.
However, this means that any form of light that stimulates the correct cones
at the correct levels will give the same perception as light of a single
wavelength (for examples of this click on,
yellow or
blue).
Color cathode ray tubes, like televisions and computer screens, (as well as
color printers and most color magazines) take advantage of this fact. If
you look closely at your color monitor, especially if you have a magnifying
glass, you can see that each pixel on the screen is actually three spots of
light - one red, one green, and one blue (hence: "RGB") - each of which emit
a narrow peak of light that roughly corresponds to one of the retina's
cones. By directly stimulating each cone to the right degree, the three
dots can give us the perception of every color in the visible spectrum - and
then some.
To understand this phenomenon we must turn, as Mach would have, to the
source of color perception, the retina. Colors are distinguished on the
retina by three different sets of cone cells, each of which detect broad peaks of
light centered around 420 nm ("blue" or short-
wavelenght cones), 534 nm ("green" or middle-
wavelength cones), and 564 nm ("red" or long-
wavelength cones). The retina assigns a "color" to a specific wavelength of
visible light according to which cones it stimulates at to what extent.
However, this means that any form of light that stimulates the correct cones
at the correct levels will give the same perception as light of a single
wavelength (for examples of this click on,
yellow or
blue).
Color cathode ray tubes, like televisions and computer screens, (as well as
color printers and most color magazines) take advantage of this fact. If
you look closely at your color monitor, especially if you have a magnifying
glass, you can see that each pixel on the screen is actually three spots of
light - one red, one green, and one blue (hence: "RGB") - each of which emit
a narrow peak of light that roughly corresponds to one of the retina's
cones. By directly stimulating each cone to the right degree, the three
dots can give us the perception of every color in the visible spectrum - and
then some.
Back to the retina. Since the retina is only able to directly detect the
activities of the receptors, it approximates the color of something by
summing the inputs of the receptors. So, in the same way that it uses
yellows and oranges to represent the simultaneous stimulation of the long- and middle- wavelength cones
in the absence of stimulation of the short-
wavelength cones, the colors "between" violet and red are invented by the
retina to explain different degrees of simultaneous stimulation of the short- and long- wavelength cones
in the absence of stimulation of the middle-
wavelength cones. The obvious question, then, is why would the retina be
designed to invent a color where there isn't one? Well, there are actually
a few very good reasons for this. From a neurological standpoint, it's
simpler: since each colored pixel is interpreted by a retinal ganglion
cells, that cell cannot send multiple outputs like "blue and red" to the
brain - this would require more cells and many more connections - so it
sends the single signal "blue+red". Since it is a single signal, it is
interpreted by the brain as a single color, "purple". From a spectral
standpoint, this is important for perceiving the "far-blues" like indigo and
violet. If you look at the above diagram, you'll notice that the red signal
stays constant as the blue signal diminishes below 420 nm; "violet" has a
lower short- to long-
wavelength stimulation ration than blue; that is: the
long- wavelength (red) cones play a part in
distinguishing violet from indigo from blue. In a way, purple, magenta, and
fuchsia are the extension of the preceived spectrum; assuming the long- wavelength inputs remained constant and the short- wavelength inputs continued to diminish through the
ultraviolet spectrum.
I suppose, part of the problem with thinking about purple may stem from
thinking of colors as defining discreet wavelengths of electromagnetic
radiation. If, instead, we think of colors as our retinas see them - as
mixes of the three primary colors - the purples have more meaning: purple is
the absence of green.
Current Queue |
Current Queue for Physics |
Physics archives
Try the links in the MadSci Library for more information on Physics.
MadSci Home | Information |
Search |
Random Knowledge Generator |
MadSci Archives |
Mad Library | MAD Labs |
MAD FAQs |
Ask a ? |
Join Us! |
Help Support MadSci
MadSci Network,
webadmin@www.madsci.org
© 1995-2001. All rights reserved.